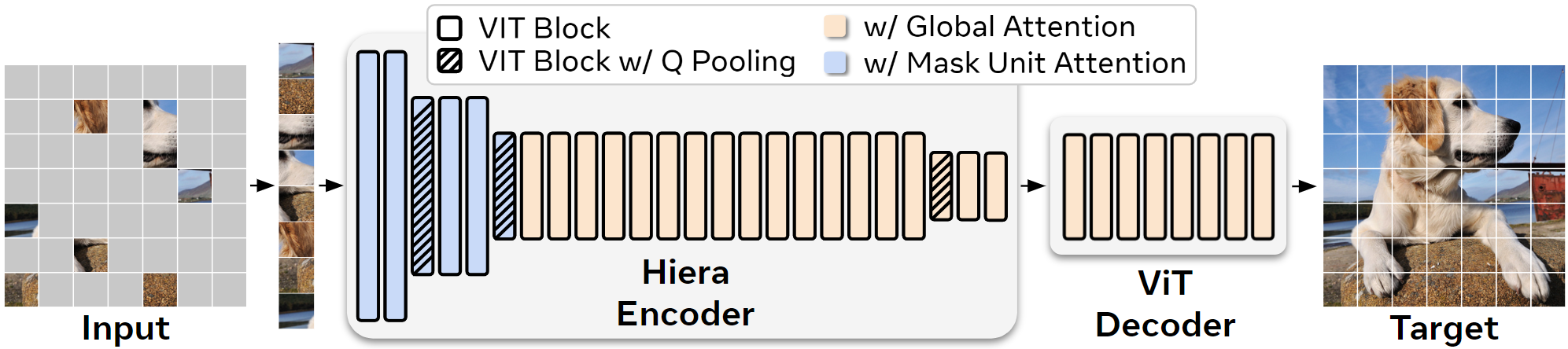
Modern multi-stage vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, this added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is actually unnecessary. By pretraining with a strong pretext task (MAE), we can strip out all the bells and whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Simple MViT, an extremely simple multi-stage vision transformer that is more accurate than previous models while being significantly faster both at inference and during training.
C. Ryali, Y. Hu, D. Bolya, C. Wei, H. Fan, B. Huang, V. Aggarwal, A. Chowdhury, Omid Poursaeed, J. Hoffman, J. Malik, Y. Li, C. Feichtenhofer
ICML (Oral), 2023.